A Tour of Computer Systems
Why Programmers Need to Understand How Compilation System Work?
- Optimizing program performance --优化程序性能
- Understanding link-time errors --理解连接时出现的错误
Avoiding security holes --避免安全漏洞
缓冲区溢出buffer overflow是导致互联网安全漏洞的主要原因
所以我们为了避免写出的代码出现安全漏洞
需要理解数据和控制信息在程序栈上是如何存储的
Programs Are Translated by Other Programsinto Different Forms
整本书的开头是通过一个helloWord简单程序的lifetime(声明周期)为线索,对计算机系统的整体概念做了一个整体的介绍。
#include<stdio.h>
int main(){
printf("Hello,world\n");
return 0;
}
首先,我们的hello程序声明周期的开始是作为一个source program/source file(源文件),也就是我们写完看到的hello.c文件。这个文件是由比特序列构成的(01串)
在大多数计算机系统中,文本是通过ASCII码来表示的,比如,上述简单的word程序变为bite串如图所示

这里插一句:
由只包含ASCII字符的文件我们称作文本文件,其他的文件被称为二进制文件。
hello.c的例子也说明了一个基本的思想:无论是disk file(磁盘文件),programs stored in memory(存储在内存中的程序),user data stored in memory(存储在内存中的用户数据),data transferred across a network(通过网络传输的数据)都可以表示为一串比特串。
区分不同对象的唯一因素是 我们查看他们的上下文!!!!
突然想起来之前有学妹问我:黑马的课程中说a的ASCII码是97,计算机存储的97的二进制,但是数字97存储的也是二进制,,这会一样的一个问题。
下面我们从宏观来说一下C语言编译的整个过程:
一开始我们创建的C语言文件是我们能够看懂的high-level C parogram
当C语言在我们电脑上运行的时候,会翻译成其他的a sequence of low-level machine-language instructions.
之后会被打包成executable object program(可执行文件)然后存储为disk file(磁盘文件)
在linux中,通过下面的命令,可以把编写的hello.c 经过compilation system编译系统(gcc)后编译成可执行程序hello
linux> gcc -o hello hello.c

在这个过程中,实际上编译系统的处理过程是十分复杂的

Preprocessor Phase(预处理):主要是根据以#开头的代码来修改原始程序,比如说这段代码中有
#include<stdio.h>会告诉processor(处理器)从系统中读取stdio.h的内容,并直接插入到程序文本中,形成一个新的文件是以.i结尾的。值得注意的是,虽然扩展名改变了,但这一步本质上只是进行了内容的修改,还是属于文本文件
Compilation phase(编译):在这一阶段会通过编译器cc1将hello.i文件编译成hello.s文件,其实就是编译成assembly-language(汇编语言)
在这一阶段,包括词法分析,语法分析,语义分析,代码生成,优化等等,见编译原理

值得注意的是,这一阶段从高级语言变成了一种文本描述的机器语言,而且这种汇编语言具有统一性,也就是说,C语言的编译器和Fortune编译器都会使用同一种汇编语言来生成输出文件。
还是文本文件
- Assembler phase(汇编):assembler(as)(汇编器)将hello.s翻译成机器指令,并把他们按照固定的规则打包,得到relocatable object program(可重定位目标文件)——hello.o文件。
Linking phase(链接):我们的程序调用了printf函数,printf函数存储在standard C library(标准C库)中,这个标准C库每个编译器都会提供,这个printf函数会驻留在一个预编译对象文件printf.o中,这个文件会通过Linker(链接器)和hello.o合并,最终成为excutable object(executable)(可执行文件)hello文件。就可以加载到内存中执行了。
也正是因为链接器可以对hello.o和printf.o进行重新调整,我们才把hello.o叫做可重定位目标文件。
Processors Read and Interpret Instructions Stored in Memory
linux> ./hello
hello, world
linux>
Shell程序是linux系统的程序。简单来说,Shell是一个命令解释程序,像cmd,cmd全称是command shell
它输出一个>提示符来等待一个命令的输入,然后执行这个命令,如果shell命令的第一个单词不是shell内置的命令,就会假设这是一个可执行文件的名字,比如上述代码中就是运行hello文件
接下来就来看一下hello程序运行时,系统发生了什么
不过在这之前,先看一下计算机的组成
Hardware Organization of a System
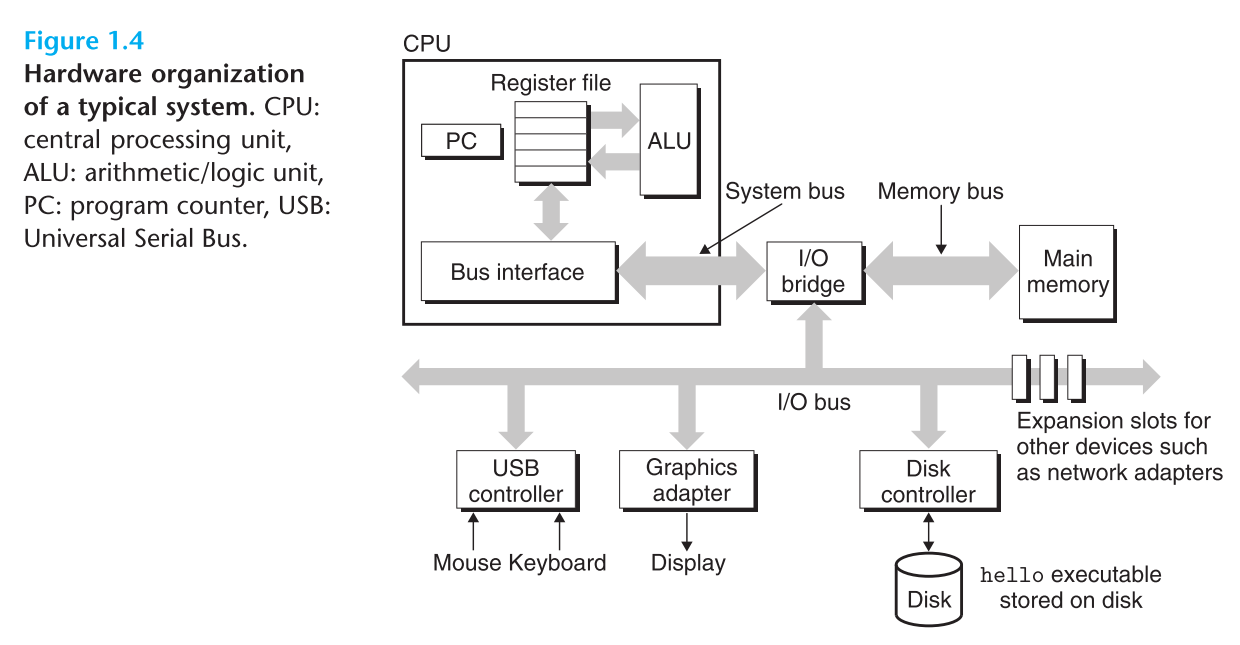
Processor
the center processing unit(CPU),processor
CPU的核心是program counter(PC),中文资料一般把PC翻译成程序计数器,但是根据原著的解释,程序计数器这五个字其实并没有很好的展示出PC的核心本质。
PC其实是一个word-size storage device(存储设备)或者是 register(寄存器)
word size(字长)会根据系统的不同而不同,对于32位的机器,1word=4byte,对于64位的机器,1 world=8byte
说白了PC就是一个4byte或者8byte的存储空间,里面存储的是一条指令的地址!
从接上电源的一瞬间到电源结束,PC一直在执行指令并且更新下一条指令的地址
但是值得注意的是,PC执行的指令并不一定是相邻的!
register file 寄存器文件
寄存器文件是由一些单字长的寄存器构成,这些寄存器都有自己的名字,寄存器是一个临时存放数据的空间。写入的时候会覆盖到之前的数据。
arithmetic/logic unit(ALU) 算数逻辑单元
计算新的数值和地址
- Load
- Store
- Operate
- Jump
Main Memory
is a temporary storage device
从物理上讲,主存是一系列dynamic random access memory(DRAM)(随机存取存储器) 芯片。
从逻辑上讲,主存可以看做一个从0开始的大数组,每个字节都有自己对应的地址
Buses
内存和处理器之间通过总线来传输数据
总线遍布了整个计算机机系统
通常总线被设计为传输固定长度的字节块,也就是word(字)
I/O Devices
输入输出设备
我们常见的有四个 鼠标键盘显示器和硬盘
IO设备通过controller(控制器)或者adapter(适配器)连入I/O bus。
- controller:主板上的芯片
- adapter:主板上的插槽
Running the hello Program
注意,这里我们会省略很多细节,主要是宏观的东西,具体的细节会在后面慢慢填充
首先,随着我们在shell程序中打入./hello之后,shell程序会将hello的字符一个一个的存入内存。
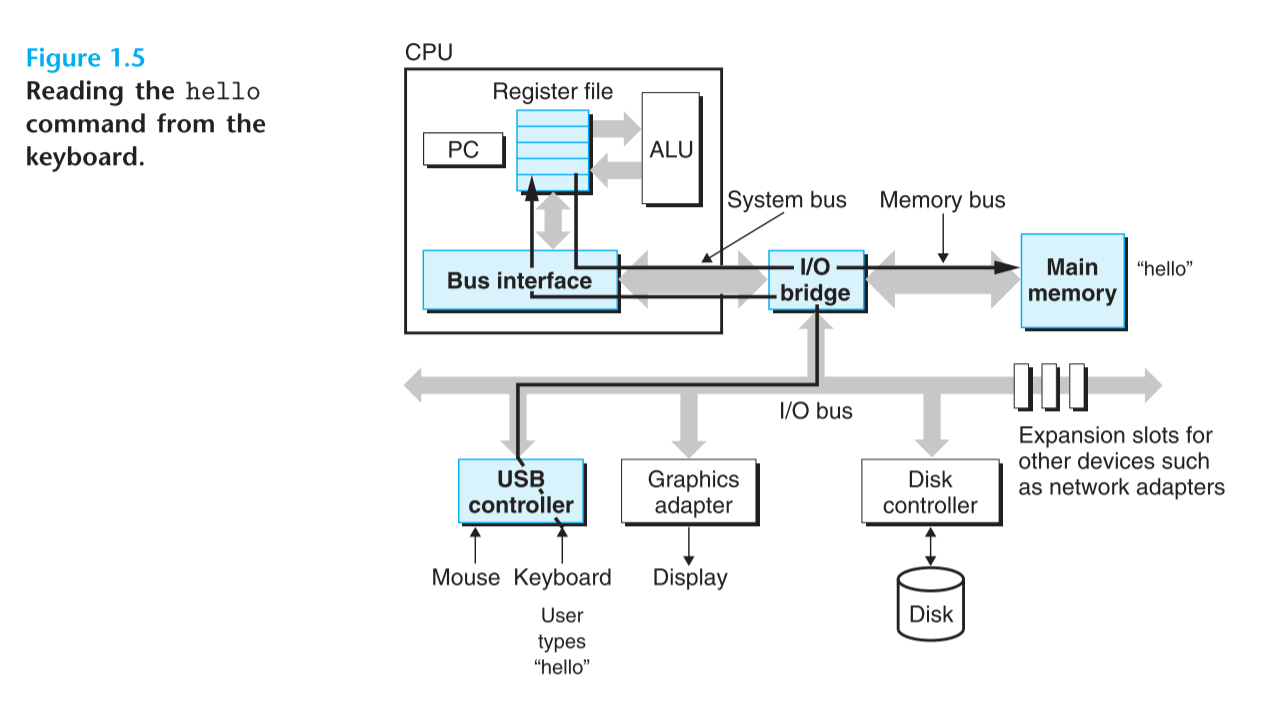
当我们在键盘上按下回车的时候,shell程序知道了我们输入完了命令,然后shell通过一系列指令来加载可执行文件hello,这些指令包括复制hello文件中的代码和数据从磁盘到主存。其中数据其实就是hello world
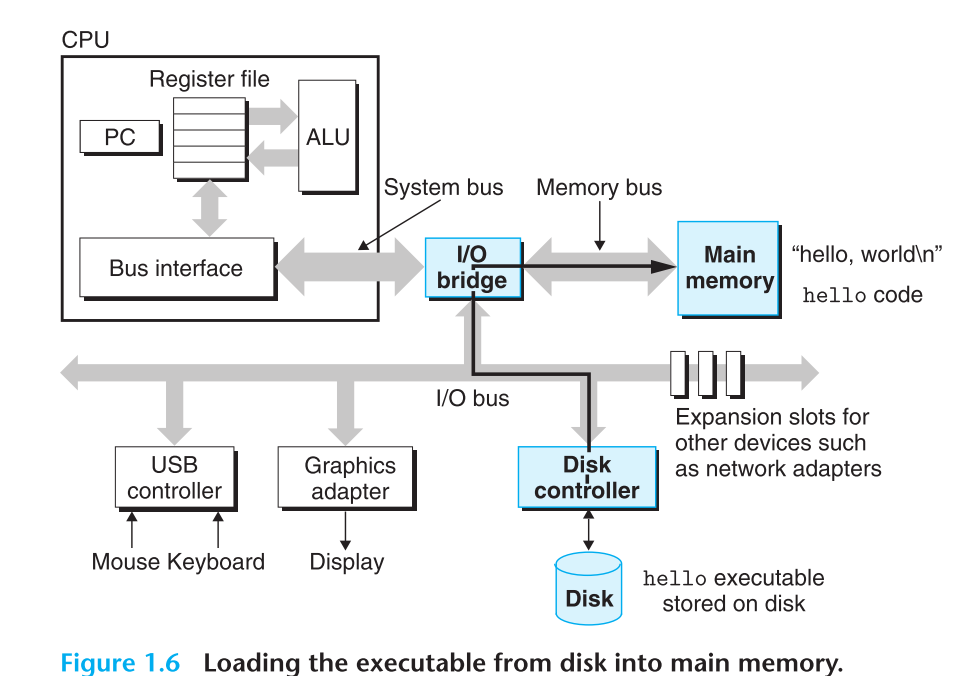
这个复制过程利用的direct memory access(DMA)技术,直接把数据从磁盘复制到了内存,并没有经过处理器。
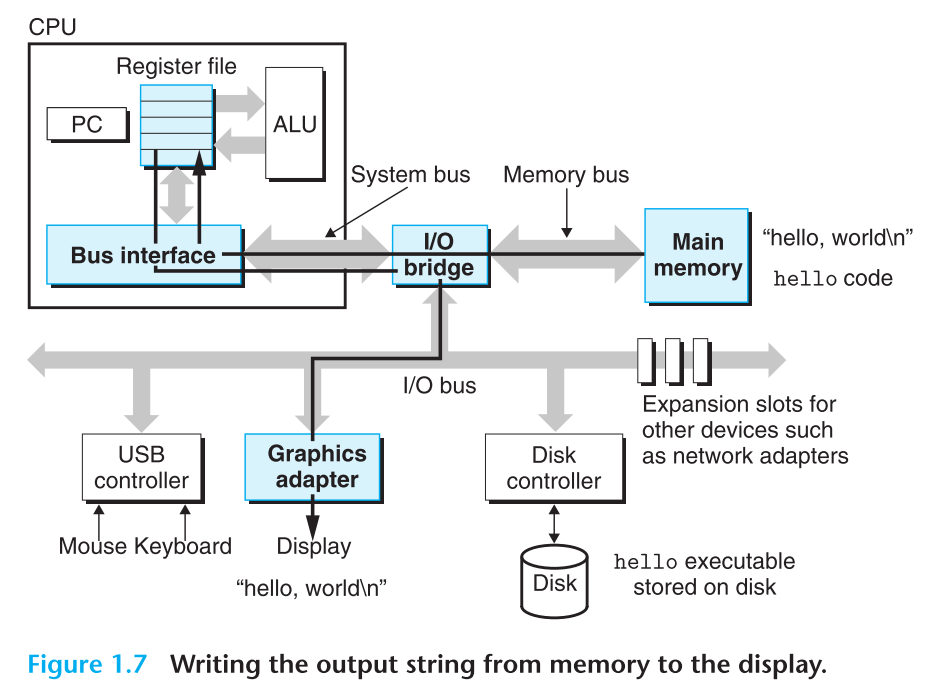
一旦代码和数据加在到了内存,处理器就会开始执行main函数中的代码。具体过程就是复制hello world这个字符串到寄存器文件,然后从寄存器文件复制到了屏幕上
Caches Matter
根据上面的流程,我们不难发现,数据频繁地在不同的地方之间传输。
但是通常情况下,大容量的存储设备的存取速度要比小容量的慢,运行速度更快的设备的价格相对于低俗设备会更贵,比如说磁盘是TB级别,而内存是GB级别,这样来看,磁盘大约是内存的1000倍,但是磁盘上读取一个字所花费的开销要比内存上读取一个字所花费的开销慢10000000倍。,而寄存器文件的大小只有几百B级别
所以处理器从寄存器读取文件的速度比从主存读取快100倍。
随着硬件的飞速发展,这样肯定是不行的。
为了减少处理器与内存之间的差距,在主存和寄存器之间引入了cache memories(caches) 高速缓存,主要是作为处理器信息的一个暂存区。缓存分为三层,越来越慢

缓存背后底层的思想其实就是利用局部性,程序是在局部区域中进行访问数据的,通过缓存来保存可能被经常访问的数据,通过缓存来执行之前大量需要内存执行的操作。
这样一来,就形成了一个层次结构
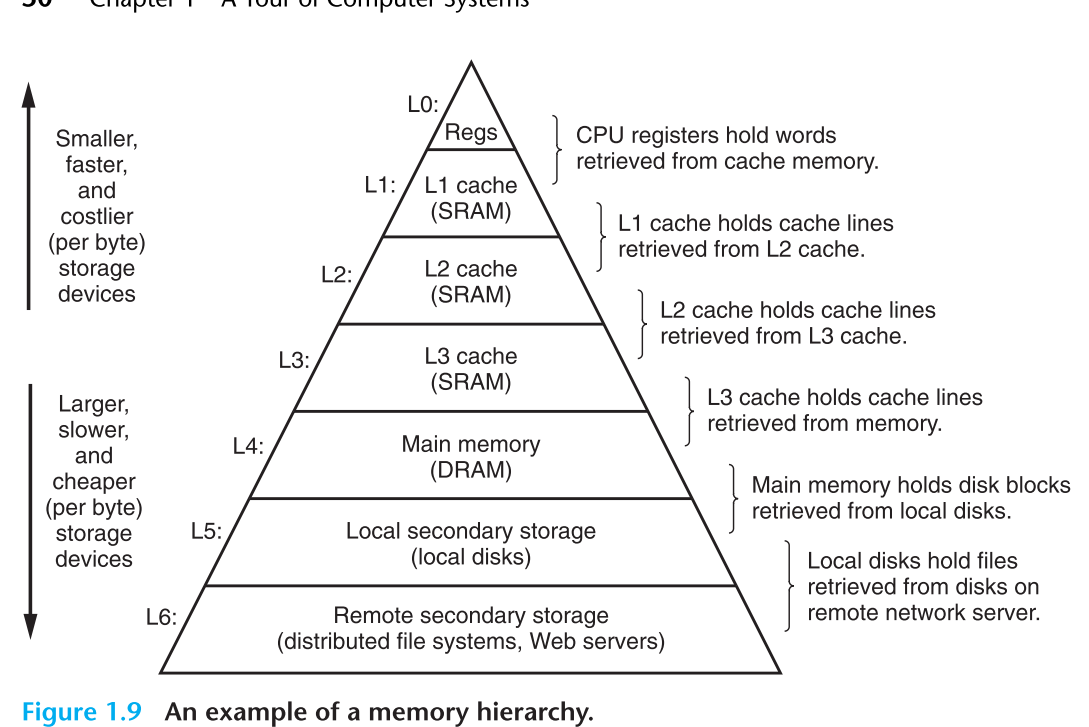
存储器分层的主要的思想是,上面一层的充当下面一层的高速缓存
The Operating System Manages the Hardware
根据上面的学习,我们发现我们的hello程序并没有直接访问键盘,显示器,磁盘和主存这些设备,而是依赖了一个东西,也就是真正操控硬件的,叫operating system(操作系统)。操作系统其实就像个软件,连接着我们的应用程序和硬件。有一个桥梁作用

这样设计的目的:
- 防止硬件被失控的程序滥用
提供统一的机制来操控所有的硬件
为了实现这样的功能,操作系统引入了几个抽象的概念:
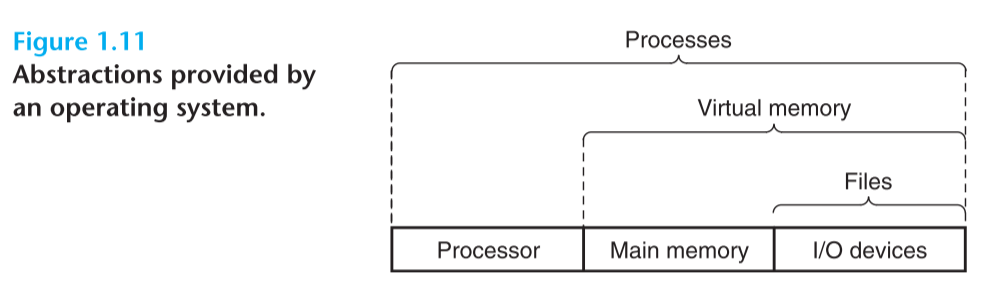
- Process 进程 对处理器,内存,磁盘的抽象
- Virtual memory 虚拟内存 对内存和磁盘的抽象
- Files 文件 对IO设备的抽象
Process
process(进程)是操作系统对于正在运行的程序的一种抽象概念。
大多数程序可以concurrently(并发)的执行在同一个系统。
对于并发,原文是这么说的:
concurrently:we mean that the instructions of one process are interleaved with the instrucitons of another process. 一个进程与另一个进程的指令交错
文章先讨论了 uniprocessor systems(单处理器系统)的情况,后面才讨论了multiprocessor systems(多处理器系统)。
为了让系统在不同process之间改变,这里系统会存储该进程的context(上下文),所谓的上下文,包括该进程运行进入下一进程前的一些信息,比如PC中的值,寄存器中的值,内存中的值等等。
之前我看过的函数调用的原理的时候,会存储一些信息,应该就是包括一些上下文和地址。
具体的过程如图所示:
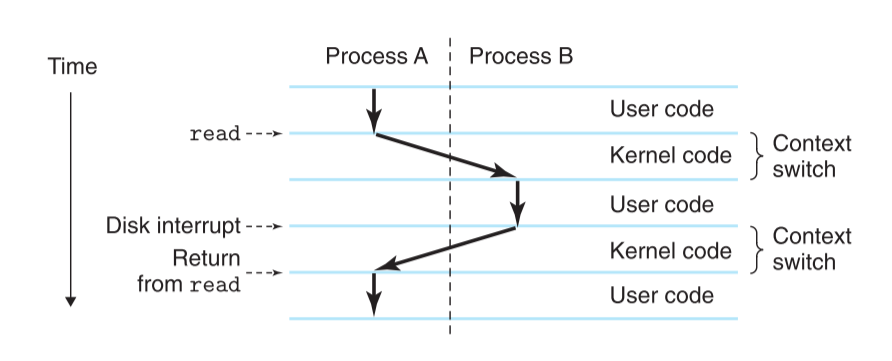
具体来说,在word程序的例子中,是从shell进程进入了hello进程。如图所示
图中我们有两个并发的进程:shell进程和hello进程
最开始的时候,只有shell进程,即shell在等待命令行的输入
当我们通过shell进程来加载hello进程的时候,shell进程通过system call(系统调用)来执行请求,系统调用会将控制权递给操作系统。
操作系统保存shell的上下文 并创建 hello进行的上下文,然后将控制权递给hello进程
hello进程运行
hello终止后,操作系统恢复shell的上下文并将控制权交还给shell,等待下一行命令的输入
在这个过程中,从一个进程到另一个进程的转化靠的是一个叫system kernel(系统内核)东西的管理。
内核是操作系统代码中始终驻留在内存中的部分。当应用程序需要操作系统执行某些操作(如读取或写入文件)时,它会执行一个特殊的系统调用指令,将控制权转移给内核。然后,内核执行所请求的操作并返回到应用程序。注意的是,内核不是一个单独的进程。相反,它是系统用来管理所有进程的代码和数据结构的集合
Threads
现代操作系统中,一个进程实际上是有多个thread(线程)组成的。
每个线程都在进程的上下文运行,共享数据的代码和全局数据。
书上说网络服务器对并行处理的需求,线程越来越重要。
据我的理解,在我们用springboot或者是我之前写过的C++中的http文件,都是考虑到了多线程的问题,这是为了防止数据堵塞。
简单来说就是 比如 不同的人同时访问同一个请求,不会阻塞
Virtual Memory
操作系统为每个进程都提供了一种假象,就是每个进程都在独自占用每个内存空间,每个进程看到的内存都是一样,这个一样的内存视图,称作virtual address sapce(虚拟地址空间)
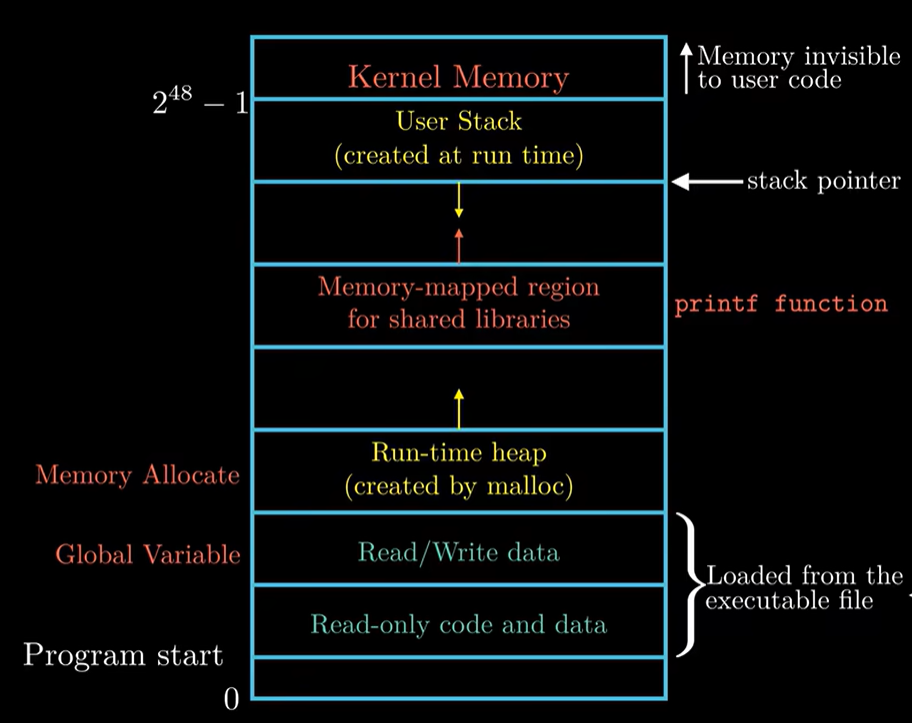
首先我们能看到下面是0地址,地址自下向上增加
Program code and data
保存的是操作系统中所有进程共用的代码和数据
这部分数据是从可执行目标文件中加载而来的, 在我们的例子中,可执行文件是hello,
对于所有的进程来说,代码都是从固定的地方开始的,就是图中的program start箭头。
放的内容:比如C语言中的全局变量等等
其他章节会有详细的介绍
Heap 堆
值得注意的是,堆不像code and data区域那样是固定大小的,堆区是随着运行程序的需要而不断扩展和收缩的。
比如C语言扩展和收缩利用的是malloc和free函数
在C语言中,我们的malloc函数所动态创建的空间实际上就创建在了堆区。
在Java中,凡是我们new的都是建立在了堆区(当时学习数组内存图的时候,黑马说的)在数组的底层也确实是这样的。
其实当时学习的数组底层原理也是这本书的一部分
Shared libraries 共享库
shared libraries是内存地址空间中间的一部分区域。
主要是保存一些共享库 比如 C standard library math library
例如hello程序中的printf函数就被存放在这里
Stack 栈 user stack
主要功能其实就是实现函数的调用。
其实函数调用的本质就是压栈
可以动态扩展和收缩
调用函数 扩展 释放函数 收缩
需要注意的是,栈的增长方向是从高地址到低地址,就是图中自上向下
其实之前在学习函数调用的原理的时候,也学习过这方面的知识。其实当时学习的哪些知识,只是这本书的一部分
Kernel virtual memor 内核虚拟内存
位于地址空间的顶部
为内核保留
不允许程序读写不允许程序调用
为了使虚拟内存能够持续工作,硬件和操作系统之间进行了复杂的交互工作,主要就是将进行的虚拟内存的内容存储在磁盘上,然后主存用作磁盘的缓冲区。
Files
linux系统的哲学本质:Everything is File
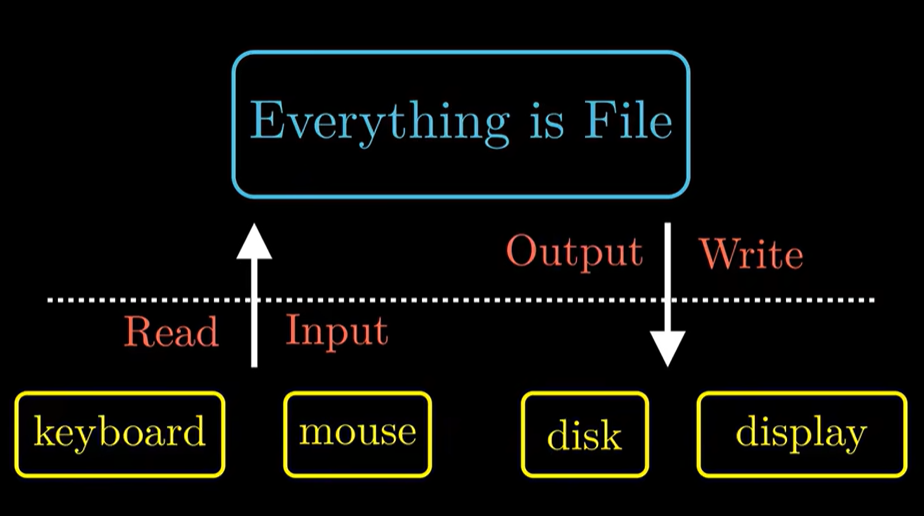
所有的IO设备,包括键盘,磁盘,显示器甚至是网络在linux中都被建模成文件。系统中的所有的读取 写入 输入 输出都是通过阅读文件和写入文件来执行的。
文件的高明之处在于,程序员不用理解内在的比如磁盘的原理是什么,仍然可以操作磁盘
Systems Communicate with Other Systems Using Networks
现代系统中,不同系统相连通过的是network(网络)
从单个网络来看,网络可以看做是一种IO设备
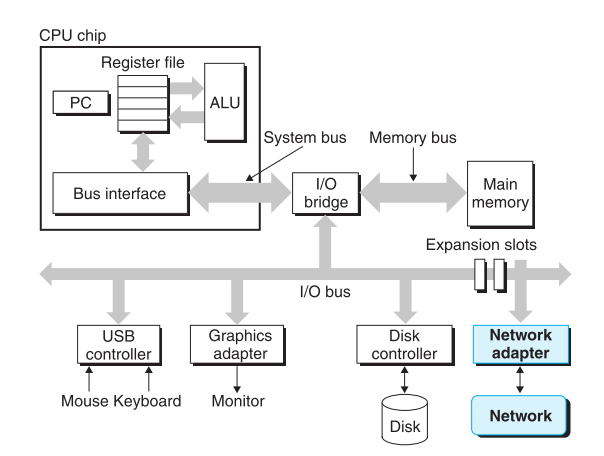
当系统发送字节序列的时候,序列会从主存复制到network adapter(网络适配器)数据会通过网络流到达另一个机器。相反的,一个系统也可以通过网络来读取其他机器发过来的数据,并把这些数据放到主存
我们通过我们hello的例子,来看一下数据传输的这个宏观的过程
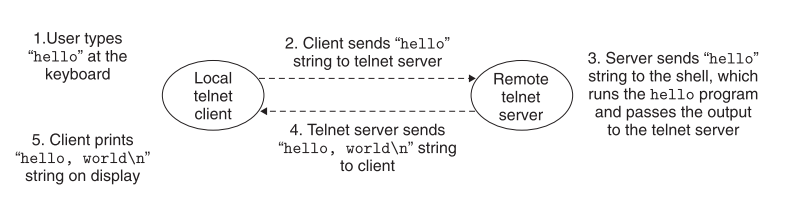

先介绍图中的两个概念,client和server
client是客户端 server是服务器
整个过程是这样的:
首先是我们remote(远程)一个机器并运行shell进程,这时候shell进程会等待我们输入命令
我们在local client的键盘上(在shell命令中输入最后的)hello并按下回车
client会发送hello去server
当server在网络上收到hello字符的时候,会把hello发送到远程的这个shell命令上,然后远程的机器的shell进程就会运行hello程序
然后把应该输出的hello world通过网络传给client。
然后client将该打印的字符串显示在屏幕上。
书上的图提到的是telnet 而视频中提到的是ssh
简单来说ssh就是telent的升级版
Important Themes
在这一章的最后,书上介绍了一些贯穿着整个计算机的概念
Amdahl’s Law 阿姆达尔定律
阿姆达尔定律主要是为了定量的来看一下系统的加速比
定律的主要思想是我们对系统的某一部分进行加速时,被加速的重要性和加速程度是影响整体系统性能的关键因素